Spark and TensorFlow for Scientific Data at Scale
¶Modern, robust, general-purpose cluster computing for data science
¶Presentation at IHPCSS 2017-06-27
¶Neal McBurnett Independent Consultant
Neal's Background¶
- Shortest commute today? 9 minute walk.
- Computer Science degrees from Brown (undergrad) and Berkeley (MS)
- Bell Labs ('77 to '01): software development, Unix/Linux, open source, WWW, IETF, security
- Internet2 Identity (PKI, etc) ('00s)
- Independent consultant
- Taught AI at University of Colorado in '12, '13
- Spark MOOC, Databricks training in '15
- Data science, Wikipedia, risk-limiting audits of elections, dance
Your Experience¶
- Python?
- Functional programming?
- Tried Spark out?
- Used it in project?
- Tried TensorFlow out?
- Used it in project?
Outline:¶
- Apache Spark is a productive framework/ecosystem for many scientific applications
- Easier to write Spark code than MPI, OpenMP
- Programming model is more expressive and helps compilers optimize for the cluster
- Builds on convergence of data analysis technologies:
- Databases: SQL, much research into query optimization
- HPC: MPI, OpenMP, etc
- Interactive exploratory data analysis: S, S++, R
- Scala and Python knack for clear, expressive, robust, high-level coding
- MapReduce: MPI, Hadoop, Spark, with huge investment from business world
- TensorFlow: for deep learning, GPU data flows and much more, also Python
- Related APIs and projects support many other applications
- Many Scientific use cases
- Huge opportunities in Machine Learning, AI
Apache Spark: popular, modern, elegant, productive¶
- The largest open source project in data processing (in 2015. Still?)
- 365 k Spark Meetup members worldwide
- Over 750 contributors from 200+ organizations, still growing
- Big turnout for our free online edX MOOC in 2015
- IBM helping to "educate one million data scientists and data engineers on Spark"
- APIs for Python (2 or 3), SQL, Java, Scala, R
- Evolved from Hadoop MapReduce, for machine learning (fast iteration)
- Brought in-memory processing for fast iteration, then much more
- Handles distributing data to nodes for you, and flexible caching
- Can read only the data needed from smart upstream data sources: "predicate pushdown" of filters
Spark components and ecosystem¶
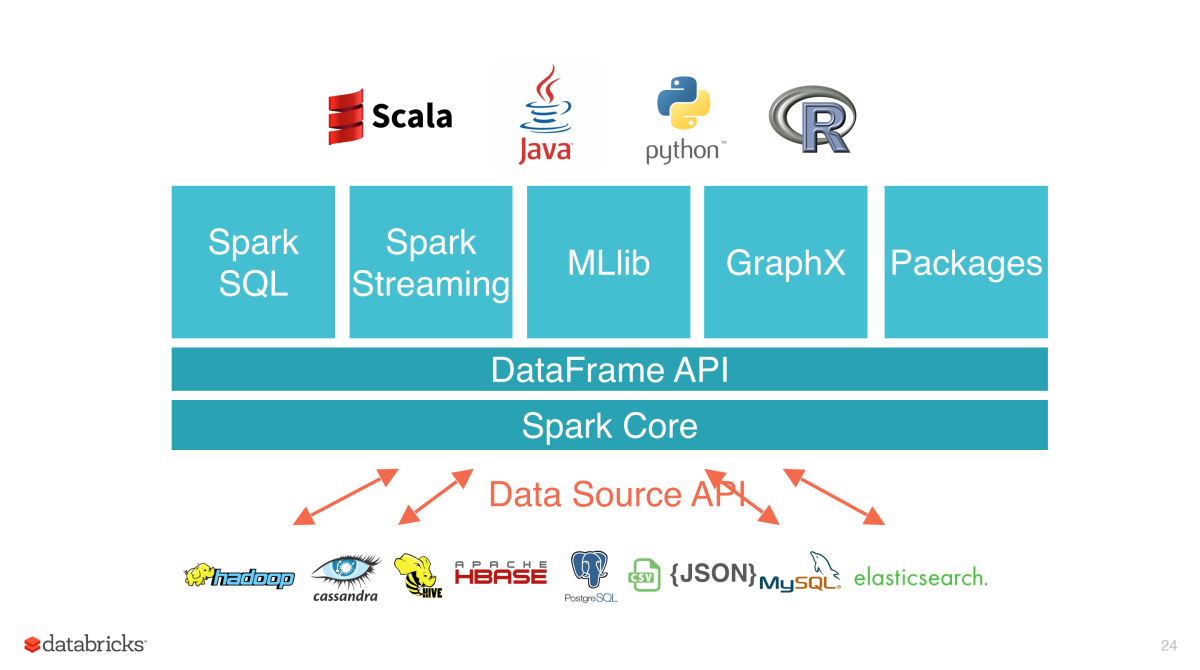
Core concept: RDD (Resilient Distributed Dataset)¶
- RDD abstraction (Resilient Distributed Datasets), core aspect of Spark programming model
- Matei Zaharia ACM Doctoral Dissertation Award
- New abstraction that led to Spark
- RDD is a collection of data, partitioned across the cluster
- Each partition can be processed in parallel
- RDD definition includes lineage - how each RDD depends on others
- In general, a Directed Acyclic Graph (DAG)
- Immutable
- Two types of RDD operations
- Transformations: modify the DAG: define new RDDs based on extisting ones
- filter, map, groupByKey, join, sort
- Actions which optimize, schedule and execute the DAG, return values
- count, reduce, lookup, save
- Transformations: modify the DAG: define new RDDs based on extisting ones
- RDDs provide fault tolerance via recalculation, avoiding data replication or failure
- RDDs can be cached to make them more persistent in memory, or temporarily saved to local disk
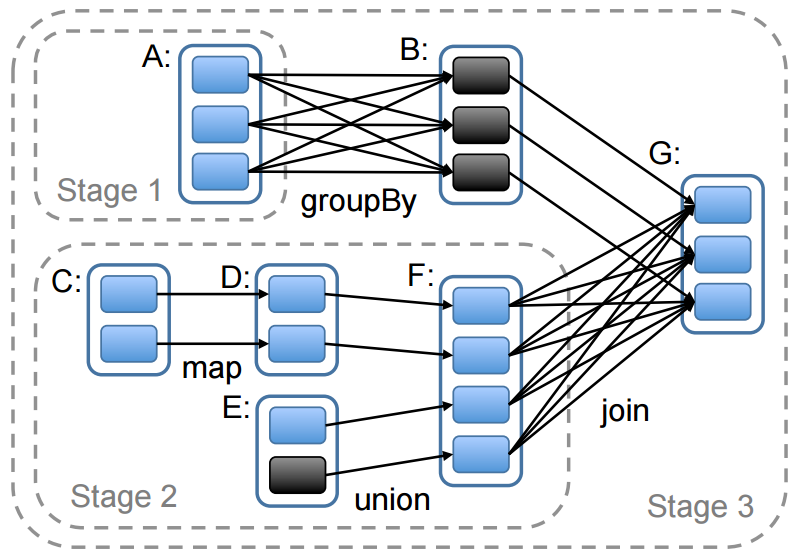
Example of a lineage of RDDs. Also shows the job stages. Boxes with solid outlines are RDDs. Partitions are shaded rectangles, in black if they are already in memory. In this case, stage 1’s output RDD (B) is already in RAM, so the scheduler runs stage 2 and then 3.
If a node dies, the partitions it was responsible for can be recalculated, knowing the lineage and the immutable inputs
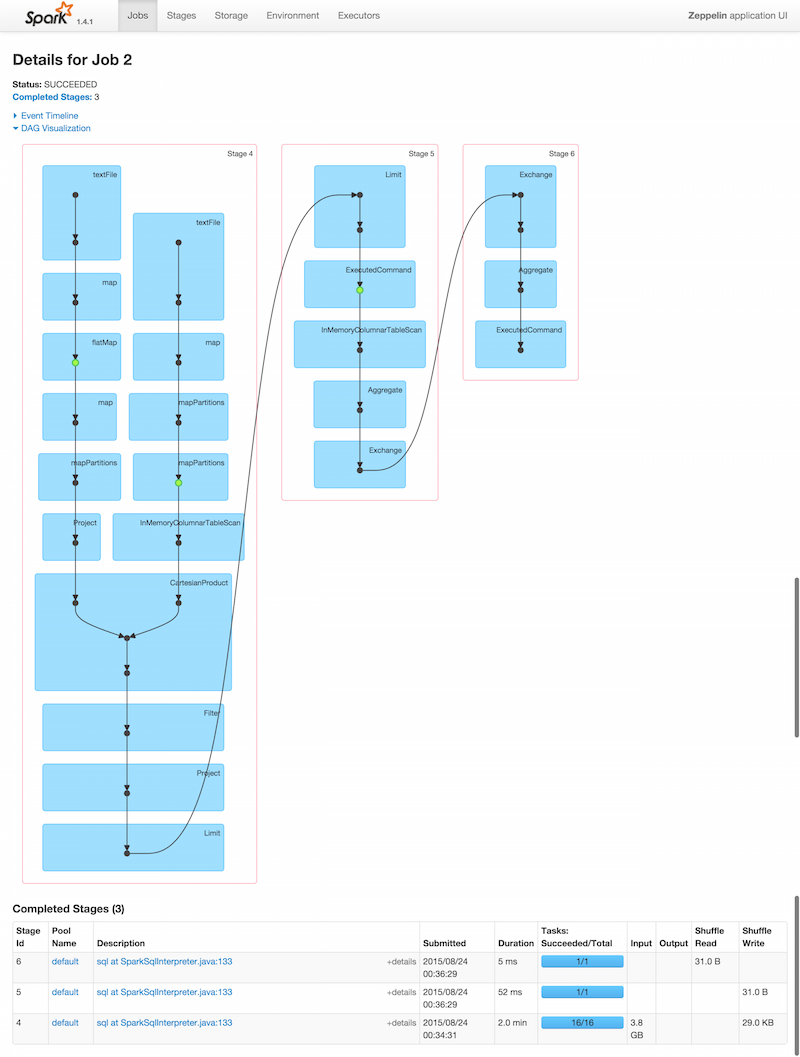
Explore Your Runtime in Spark UI¶
Real-time graph of the DAGs in your jobs, stage progress, storage, environment, nodes
Spark code compiled into efficient execution plan for the cluster¶
Something like compilers optimizing for pipelined CPUs
Compiler, DAG helps avoid failures, deadlock
Spark mashes functional programming up with SQL optimizing technology
- Catalyst compiler for parallel computations on your cluster
Code describes Directed Acyclic Graph
- Lazy evalution - not evaluated until you perform an
action - Compiler can use full DAG, desired action, and even data contents, to make an optimized execution plan
- Lack of side effects in functional programming enormously useful in parallel processing
- Review and make use of your abstract algebra classes!
- See Paco Nathan, Just Enough Math - O'Reilly Media
- With links to over an hour of free video on functional programming and monoids for cluster computation
- Lazy evaluation makes exploration, debugging quicker
Even higher-level API: Datasets and DataFrames¶
- DataFrame API: Higher level than RDD, inspired by Pandas and R data frames, combined with SQL engine
- More optimizations possible than with RDD
- Unified with more general Datasets API in Spark 2.0: DataFrame = Dataset[Row]
- Internally leverage the Spark SQL logical optimizer. Intelligently plan the physical execution of operations to work well on large datasets. This planning permeates all the way into physical storage, where optimizations such as predicate pushdown are applied based on analysis of user programs.
- Create Datasets directly from Hive tables, Parquet files, Spark SQL, etc.
Even More Higher-level APIs¶
You can do lots of things with your data in Spark
- MLlib - original Spark Machine Learning API, distributed implementations of many algorithms
- ML - elegant API for machine learning, inspired by scikit-learn pipelines
- 2017: Deep Learning Pipelines for Apache Spark integrates with TensorFlow and Keras
- Lets you use TensorFlow as just another transformer in your machine learning pipeline
- Spark SQL makes Spark accessible to many more people: analysts, managers
- GraphX to bring graph processing to big data sets
- Streaming, unified with batch processing
Scientific use cases for Spark¶
- Researchers exploring data interactively with tools like Jupyter notebook, Databricks
- The same code can be evolved into an efficient production system
- See e.g. SciSpark from NASA: Automated Search for Mesoscale Convective Complexes
- Fault tolerance allows running on less expensive hardware
- Portability: run your code on a laptop, or a variety of clusters: local, community, commercial clouds
- Jupyter notebooks can even be used to write papers, make presentations, easy to share actual code and explorations. Reproducable science
- Machine learning at scale
- Combining streaming and batch processing for real-time data products (weather forecasts etc.)
- Pre-process datasets: Extract, Transform, Load (ETL) with modern tools
- NASA use of MapReduce in Hadoop for MERRA/AS (Modern Era Retrospective-Analysis for Research and Applications Analytic Services). Augments netCDF files with indexes in HDFS. Could integrate with Spark.
- Post-process data
- Stream simulation results into a Spark analysis pipeline
- Parallelize and process results from other tools: scikit-learn, Pandas, anything you can run on a node
- Hyperparameter tuning for models using grid search with cross validation, e.g. with deep learning / TensorFlow via new Databricks code
- Even for more traditional HPC? Rethinking paper with case studies in astronomy (Spark-mAdd) and genomics (ADAM)
- Faster than HPC state-of-the-art for some tasks, organizing around data formats like Parquet which are designed for parallelization and compression.
Practicalities and Challenges¶
- Most of the runtime and libraries are Scala or Java, cleverly integrated with Python
- System is running on Java Virtual Machine behind the scenes
- So error messages can be confusing
- If partition in an RDD is larger than a node's memory, it spills to disk, can trash performance
- So factor into application design, or size your cluster to match your data, or have SSDs on your nodes
"HPC systems are the mirrored image of data centers.¶
In a data center, the file system is optimized for latency (with local disks) and the network is optimized for bandwidth.¶
In a supercomputer, the file system is optimized for bandwidth (without local disk) while the network is optimized for latency." - IPCC¶
Not the Intergovernmental Panel on Climate Change....
The other IPCC: Intel Parallel Computing Center at Lawrence Berkeley Lab
IPCC is working to adapt Spark, which came from the world of data center clusters, to the supercomputer world.
Note: Yellowstone: no local disks on nodes
SDSC Comet (via XSEDE) does have local disks, for workloads that benefit
TensorFlow¶
- Open source library from Google for numerical computation using data flow graphs
- Known for deep learning, neural networks, machine learning in general, but much more general, like distributed numpy
- Now more machine learning APIs, e.g. K-means, SVM (Support Vector Machines), and Random Forest
- Python API
- Fast code to analyze and run the graph
- Optimized for GPUs as well as CPUs
- Much more high level and easier to write code than OpenACC
- Describe a data flow graph of operations on tensors (n-dimentional arrays) and then run it
- Tough to build and install. Good advice at Deep Learning Garden – Liping Yang's machine learning and deep learning home: TensorFlow
Machine Learning, Artificial Intelligence and Science¶
- Enormously exciting time in history
"Artificial Intelligence, deep learning, machine learning — whatever you’re doing if you don’t understand it — learn it. Because otherwise you’re going to be a dinosaur within 3 years." — Mark Cuban, 2017
Get on board with machine learning
- Put it to use in AI
- Foresight Institute workshops on nanotech from atomic scale on up
- AI for Scientific Progress Workshop October 2016
Related projects¶
- Apache Parquet: columnar storage format with great parallelization, compression, flexibility
- Ceph: highly parallel object storage ala Amazon S3, along with other capabilities.
- Apache Arrow: columnar in-memory data layer between Spark, Pandas, Parquet, Drill, etc: reduce serialization overhead
- Apache Beam: Batch and strEAMing dataflow model and API from Google.
- TensorFlow: open source library for numerical computation using data flow graphs
- Apache Giraph: iterative graph processing, with similarities to MPI
Summary¶
- Spark and TensorFlow have many applications for scientific computing
- It helps you be more productive at writing code and analyzing data
- Cluster optimizers make your code faster
- Spark popular due to speed, flexibility, blend of interactive investigative analytics, batch data analytics, streaming updates
- TensorFlow already popular for deep learning, GPU lots more potential
- Use Spark to run lots of TensorFlow jobs in parallel: parameter tuning via grid search
- Lots of training opportunities and experience out there due to popularity
- Runs in lots of environments, easier to develop on laptop, test on small cluster, redeploy on big one or in the cloud
- Friday plenary hands-on at bridges with John Urbanic on Spark (K-Means clustering; Recommender System) and TensorFlow: handwritten digit recognition
Thanks to:¶
- Insights and motivation from the Boulder Data Detectives LinkedIn Group (Wednesdays at BJ's)
- Deep insights from Sameer Farooqui, Brian Clapper, and the rest of the team at Databricks Training
- Great examples of Spark applications in climate science by Anderson Banihirwe and Kevin Paul
- Zebula Sampedro, Dan Milroy and Davide Del Vento for original spark-setup-scripts, for running Spark on Janus and Yellowstone
- TensorFlow insights and help from Liping Yang
Questions? Neal McBurnett neal.mcburnett.org
Explore more....¶
This presentation:
SEA Class and Hands-on Workshop: Spark and TensorFlow (NCAR) related presentations and code, more on TensorFlow
- Rethinking Data-Intensive Science Using Scalable Analytics Systems | AMPLab – UC Berkeley: ADAM (genomics) and Spark-mAdd (astronomy)
- Hail: Scalable Genomics Analysis with Apache Spark - Cloudera Engineering Blog
- How JupyterHub tamed big science: Experiences deploying Jupyter at a supercomputing center: JupyterCon, August 22 - 25, 2017, New York, NY
- AI for Scientific Progress Workshop Foresight Institute, October 2016
- Spark Summit 2017 Schedule - a month ago
- Apache Spark on Supercomputers: A Tale of the Storage Hierarchy | Spark Summit 2017
- TensorFlow On Spark: Scalable TensorFlow Learning on Spark Clusters | Spark Summit 2017
- Apache Spark MLlib's Past Trajectory and New Directions | Spark Summit 2017
- Improving Python and Spark Performance and Interoperability with Apache Arrow | Spark Summit 2017
- Data Wrangling with PySpark for Data Scientists Who Know Pandas | Spark Summit 2017
- Taking Jupyter Notebooks and Apache Spark to the Next Level PixieDust | Spark Summit 2017
- Applying SparkSQL to Big Spatio-Temporal Data Using GeoMesa | Spark Summit 2017
- GPU-Powered Deed Learning in the Spark Ecosystem | Spark Summit 2017
- Real-Time Machine Learning with Redis, Apache Spark, TensorFlow, and more | Spark Summit 2017
- Deep Learning to Big Data Analytics on Apache Spark Using BigDL | Spark Summit 2017
- Applying Apache Hadoop to NASA’s Big Climate Data Use Cases and Lessons Learned Glenn Tamkin (NASA/CSC) for MERRA: ApacheCon, 2015-04-13
- SciSpark/SciSpark: Scientific Spark - a NASA AIST14 project at JPL, e.g. their Grab 'em, Tag 'em, Graph 'em (GTG) software for identifying mesoscale convective complexes via feature detection, evolution and feature characterization
- Scaling Spark on HPC Systems - from LBL/IPCC
- Matrix Factorizations at Scale: a Comparison of Scientific Data Analytics on Spark and MPI Using Three Case Studies - Spark Summit 2017 video and slides and paper on arxiv
- An Introduction to Apache Spark - Zebula Sampedro - Rocky Mountain Advanced Computing Consortium conference, 2015: including examples run on JANUS, which our Yellowstone Spark scripts are based on.
- spark-setup-scripts for Janus (and Yellowstone, under construction)
- Putting Some Spark In HDF-EOS | HDF BLOG
- Snorkel: Dark Data and Machine Learning | Spark Summit 2017 video and slides for labeling images etc. and creating training data sets
- Data Container Project: structuring HDF5 file collections for improved performance
- Parallel I/O – Why, How, And Where To? | HDF BLOG
Data Science and Engineering with Spark | edX - 5 free MOOC courses, 18 weeks, starts May 2016
Paco Nathan, Just Enough Math - O'Reilly Media with some free video on functional programming and monoids for cluster computation
CU Research Computing Intro to Spark, by Dan Milroy with IPython notebook examples.
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing - Usenix NDSI 2012 best paper, Matei Zaharia et al. Video of Talk
- Spark et al. contrasted with MPI (HPC): fault-tolerant and easier to code but not as performant?
- Jupyter / IPython notebook hints and tips - Nelis Willers